Kohya_ss を使用した LORA のトレーニング 【チュートリアル】


はじめに
こんにちは、皆さん。今日は、画像の生成と操作に関する面白いオープンソースプロジェクトを紹介したいと思います。その名もKohyaです。Kohyaは、拡散ベースのモデルを使って、画像を自然に生成したり、変換したりできるツールです。拡散ベースのモデルとは、画像を徐々にノイズに置き換えていき、その逆の過程で元の画像を復元するように学習したモデルのことです。この方法は、画像の品質が高く、多様性が豊かであることが特徴です。Kohyaは、この技術を使って、さまざまな画像生成や操作のタスクに挑戦しています。例えば、顔や動物の画像を生成したり、スタイルや表情を変えたり、テキストから画像を作ったりできます。Kohyaは、誰でも簡単に使えるように、ウェブサイトやコマンドラインツールを提供しています。もちろん、ソースコードも公開されているので、自分でカスタマイズしたり、改良したりすることもできます。Kohyaは、画像生成と操作の分野で革新的なプロジェクトだと思います。興味のある方は、ぜひチェックしてみてください。
Kohya_ssの詳細については、プロジェクトの Github ページを参照してください。
インストールの方法に関してはこちらに記載しています。
LORAトレーニング用の画像の準備
LORAをトレーニングするために必要な画像は、すべて同じフォルダーに入れます。自分や他のキャラクター、物体、スタイルなどの画像を使っても構いません。
キャラクターについては、高品質な画像を10枚だけ使っても、効果的なLORAを訓練できます。しかし、画像の数が多ければ多いほど、LORAはより信頼性と細かさを持ち、AIが生成する画像の質も向上する可能性が高まります。
高画質な画像を探すためのいくつかの方法を紹介します。
Google 画像検索
Google画像検索は、インターネット上の画像を様々な条件で検索できる便利なツールです。しかし、時には高解像度の画像が欲しいときもありますよね。例えば、壁紙やプレゼンテーションに使いたいときなどです。そんなときに役立つのが、検索オプションと高度な検索です。検索オプションは、Google画像検索の画面右上にある歯車のアイコンをクリックすると出てきます。そこで、「大」を選択すると、大きなサイズの画像だけが表示されます。これだけでもかなり絞り込めますが、もっと細かく指定したい場合は、高度な検索を使いましょう。高度な検索は、検索オプションの中にある「高度な検索」をクリックすると出てきます。そこで、「画像サイズ」の項目で、「4〜6MPより大きい」を選択すると、さらに高解像度の画像が見つかります。これらの方法で、Google画像検索で高解像度の画像を探すことができます。もちろん、他にも色や形式などの条件も指定できますので、自分の目的に合わせて試してみてください。また、ストック画像サイトや映画のスクリーンキャップサイト、ウィキメディアなども高解像度の画像が豊富にありますので、参考にしてください。
ダウンロード画像に連番を付けて、📂フォルダに詰め込んでください。
画像にキャプションを付ける 1 (タグ消し不可)
画像にキャプションを付けるには、Kohya Utilities > Captioningを使うと便利です。
BLIPとWD14キャプションはよく使われるものですが、構造が違うので、自分の目的に合ったものを選んでください(私は時々両方使います)。
画像ファイルのパスとトリガーワードを入力して、Caption images を押してください。
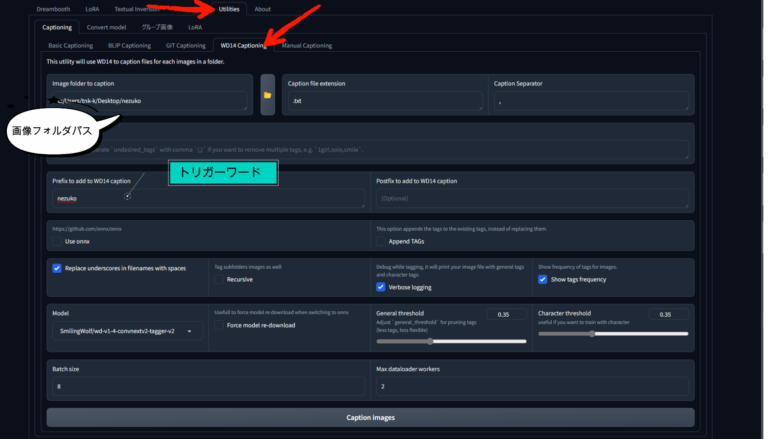
少し時間が掛かりますが、画像ファイル内にテキストが追加されます。

画像にキャプションを付ける 2 (タグ消し)
トレーニング用のフォルダの準備
Kohyaを使用して、独自のLORAを作成するために必要ないくつかのフォルダを作成します.
起動方法はKohyassフォルダの gui をダブルクリックしたて、URL http://127xxxxを機キーボードのCTRLを押しながらクリックすればきどうします。
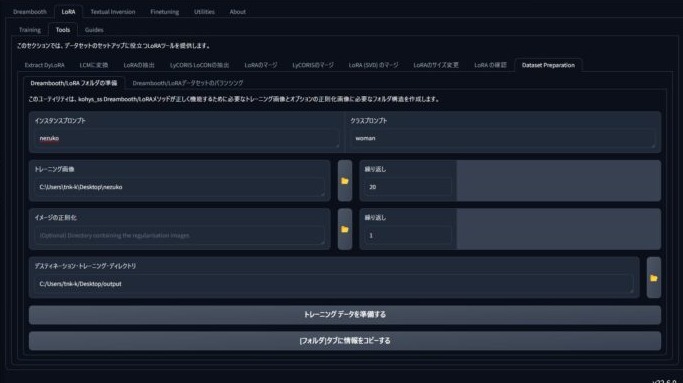
- Lora > Tools > Dataset Preparationにアクセスします。
- Instance promptインスタンスプロンプト: トレーニングしたいユーザーの名前を入力します。例: nezuko
- Class prompt(クラスプロンプト): woman、man、object、person、style、dog などのカテゴリーを入力します。
- Training images(トレーニング画像): 画像を用意したフォルダーを選択します。
- Repeats(リピート): トレーニングの回数を指定します。20 は安全な値です。
- 正則化画像: カテゴリーに対応する高解像度画像がたくさん入ったフォルダーがあれば、それを利用できます。私は使いませんが、結果はとても良いです! しかも、正則化画像なしでトレーニングする方が早く終わります。
- Destination training directory: トレーニング用のフォルダーを作成する場所を指定します。
- フォルダー内に📂Image 📂log 📂model フォルダが作られます。
- 📂Image イメージフォルダの中に学習画像のフォルダが作られていますので、画像を移し替えてください。
- Prepare training data(トレーニング データを準備する)を押す。
- 画像とテキストが📂Imageフォルダに移動します。
画像とフォルダーの準備ができたので、Kohya を使って自分だけの SDXL LORA モデルを学習させることができます。
では、さっそく学習を始めます。
Loraをトレーニングする方法–Kohya設定
SDXL LORA モデルの学習に必要な設定を説明します。 一般的なローラ学習と同じ手順に従いますので、参考になると思います。
SDXLモデルの準備
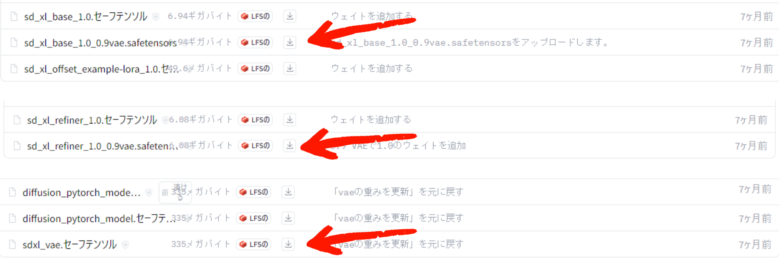
SDXL LORA モデル学習では、通常のcheckpointでは動きませんので、SDXLモデルを準備する必要があります。 今回は
sd_xl_base_1.0_0.9vae.safetensors をつかいます。 Stable Diffusionでも使える様にsd_xl_refiner_1.0_0.9vae.safetensors と
sdxl_vae.セーフテンソル も 入手しておきます。
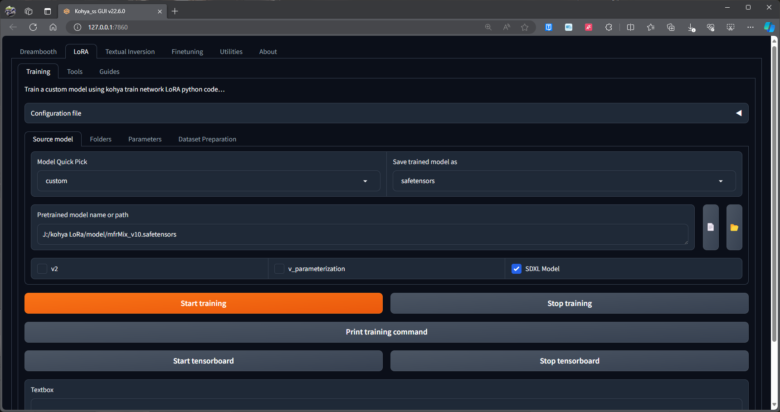
Source model タブ設定
LoRAタブの中のTrainingタブの中のSource modelタブの設定を行います。
- Model Quick Pick ➡️ custom カスタムを選択
- Pretrained model name or path事前トレーニング済みモデルの名前またはパス
- 先ほどダウンローしたsd_xl_base_1.0_0.9vae.safetensorsのパスを記載、又は、横の📃ボタンでcheckpointを指定します。
- Save trained model as ファイルの種類をきりかえます。
- SDXL modelのチェックボックスに✔を入れる。 通常タイプのLoRa学習の場合は✔を外す
Folders タブ設定
トレーニング用のフォルダの準備で作ったフォルダを指定します。
- Image folder 画像が入っているフォルダの親フォルダを指定、(Image)
- Output folder 出力フォルダ、(model)
- Regularisation folder正則化フォルダー (未設定 Or 画像が有ればパスを記載)
- Logging folder ログ保管ホルダ (log)
- Model output name ファイル名とバージョン№
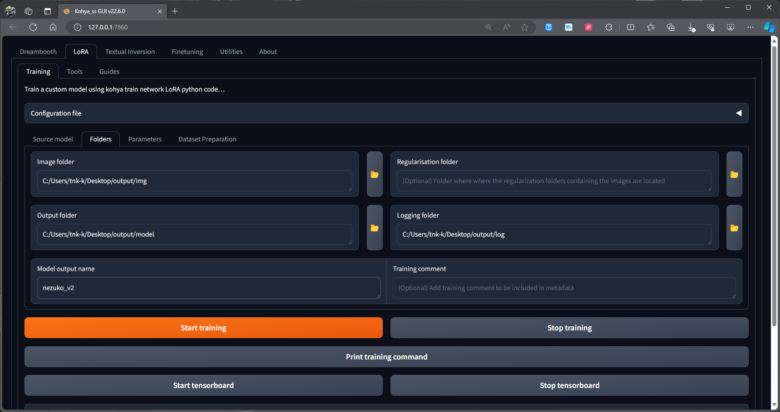
Parameters タブ設定
NVIDA GeForce RTX3080 Ti で、使用率80%の設定です。
- Presets SDXL – LoRA aitrepreneur clothing v1.0 (全ての設定が自動で変換されます)
- Train batch size 4 書き換え
- Epoch 20 (学習回数です、20~30程度が目安)書き換え
- Save every N epochs 5 書き換え
- Caption Extension txt
- Mixed precision と Save precision bf16
- Learning rate 0.001 書き換え
- Max resolution 1024×1024 (SDXL最低解像度)
- Text Encoder learning rate 0 書き換え
- Unet learning rate 0.0009
- SDXL Specific Parameters
- Cache text encoder outputs ✔
- Network Rank (Dimension) 128
- Network Alpha 1
設定がめんどくさい方は 📂kohya_ss の中の📂presets の中に📂lora が有りますので、 その中のSDXL – LoRA aitrepreneur clothing v1.0を取り出し、下のファイルに入れ替えてください、VRAM12GBのビデオボードなら、動くはずです。
設定が終われば Start training を押す。
画像フォルダ内にnpzファイルが追加され、学習がはじまります。
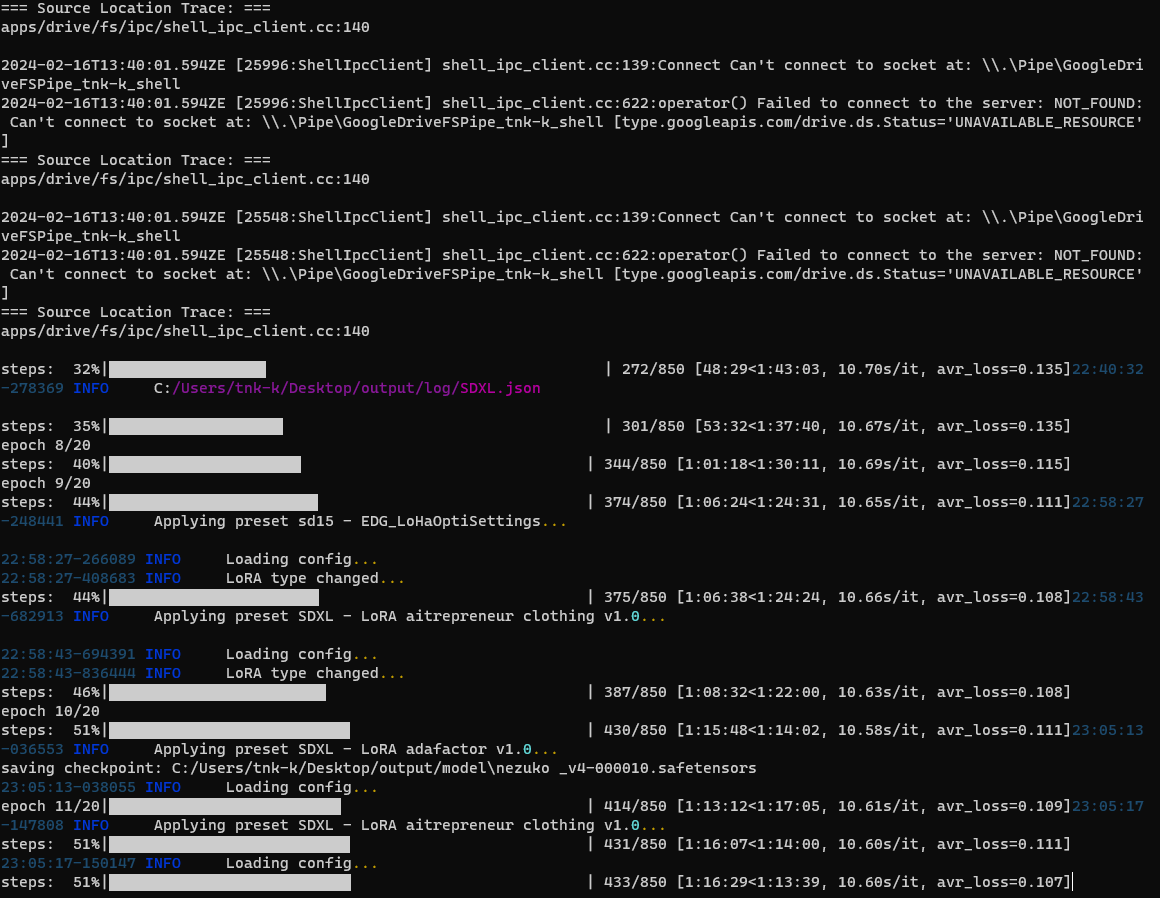
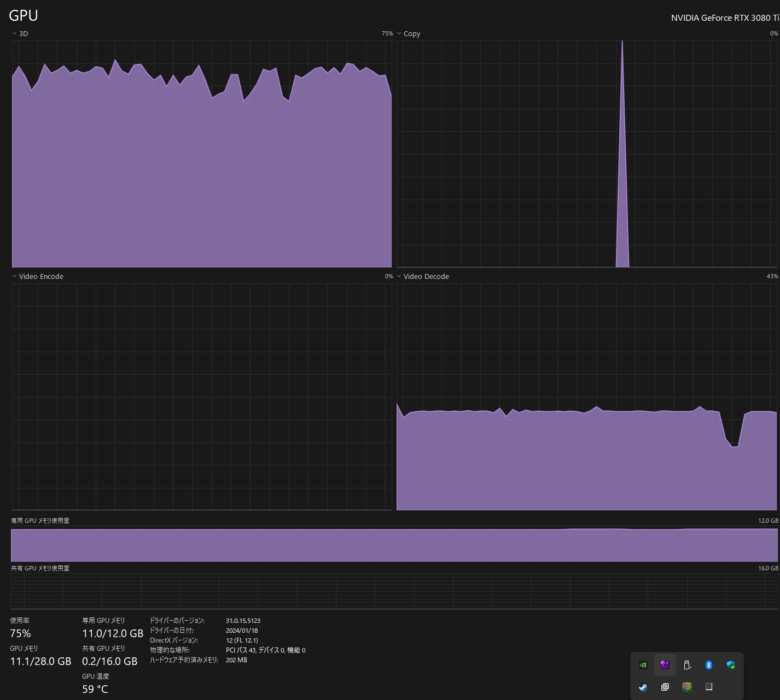
エラーで止まる場合はこちらの記事を参考にしてください。
学習結果
学習画像の数×繰り返し回数: 340
正則化画像の数: 0
1epochのバッチ数: 85
epoch数: 20
バッチサイズ: 4
勾配を合計するステップ数 = 2
学習ステップ数: 850
学習時間 2時間 30分
プロンプト
1girl,kamado nezuko,solo,japanese clothes,long hair,kimono,pink kimono,bit gag,gag,looking at viewer,black hair,ribbon,multicolored hair,very long hair,hair ribbon,sash,obi,pink eyes,haori,gagged,floating hair,bamboo,pink ribbon,long sleeves,checkered sash,mouth hold,sharp fingernails,gradient hair,forehead,two-tone haircheckpoint
sd_xl_base_1.0_0.9vae.safetensors + sd_xl_refiner_1.0_0.9vae.safetensors


最後に
(_´Д`)ノ~~オツカレーさまでした。SDXL LoRA学習は高性能なビデオボードが必要なため、情報量が非常に少ないと感じました。通常のLoRA学習の3倍は時間がかかりますし、VRAM 12GB以上の高性能グラボが必要です。また、VRAMの節約のために、オプション機能を追加する必要がありました。エラーもいろいろと経験しましたので、エラー回避の方法などをお伝えできればと思います。