comfyUI 初心者の覚書 ① 【背景とキャラクター設定】


初めに
comfyUIではノードの組み合わせが理解できなかったため放置していましたが、stable-diffusion-webuiでアニメーション制作の限界を感じ、少し試してみることにしました。初心者としての悪戦苦闘の記録を残していきます。
インストール方法については記述しておりませんので、他のウェブサイトを参照してください。
最初の生成画像
comfyuiを起動すると、サンプルノードが表示されます。これは最低限必要な組み合わせであり、ここにノードを追加することで機能を拡張していきます。
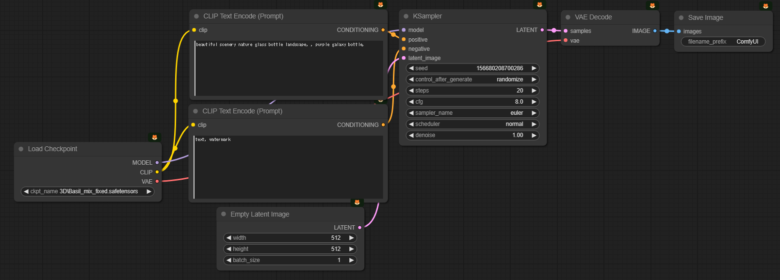
Load Checkpoint を Checkpoint Loader 🐍に変更する
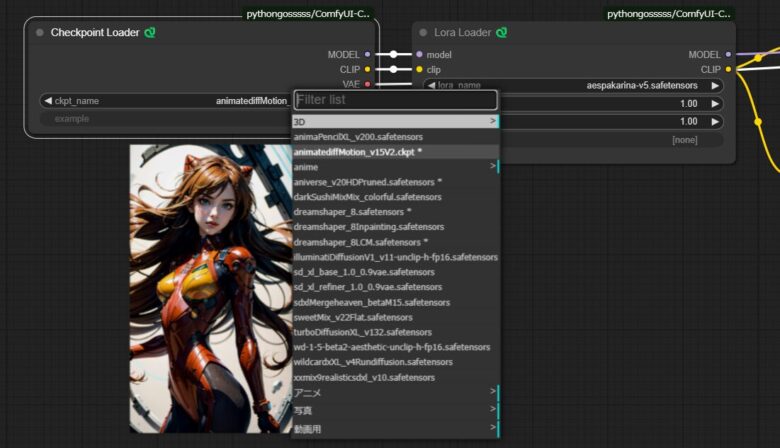
Load CheckpointとCheckpoint Loader 🐍の主な違いは、プレビュー表示の有無です。stable-diffusion-webuiではプレビュー画像を見ながらCheckpointを選ぶことができるため、私は常にそれを切り替えて使用しています。LORAのノードについても、同様にLora Loader 🐍を使用しています。
ノード名は pythongosssss です。
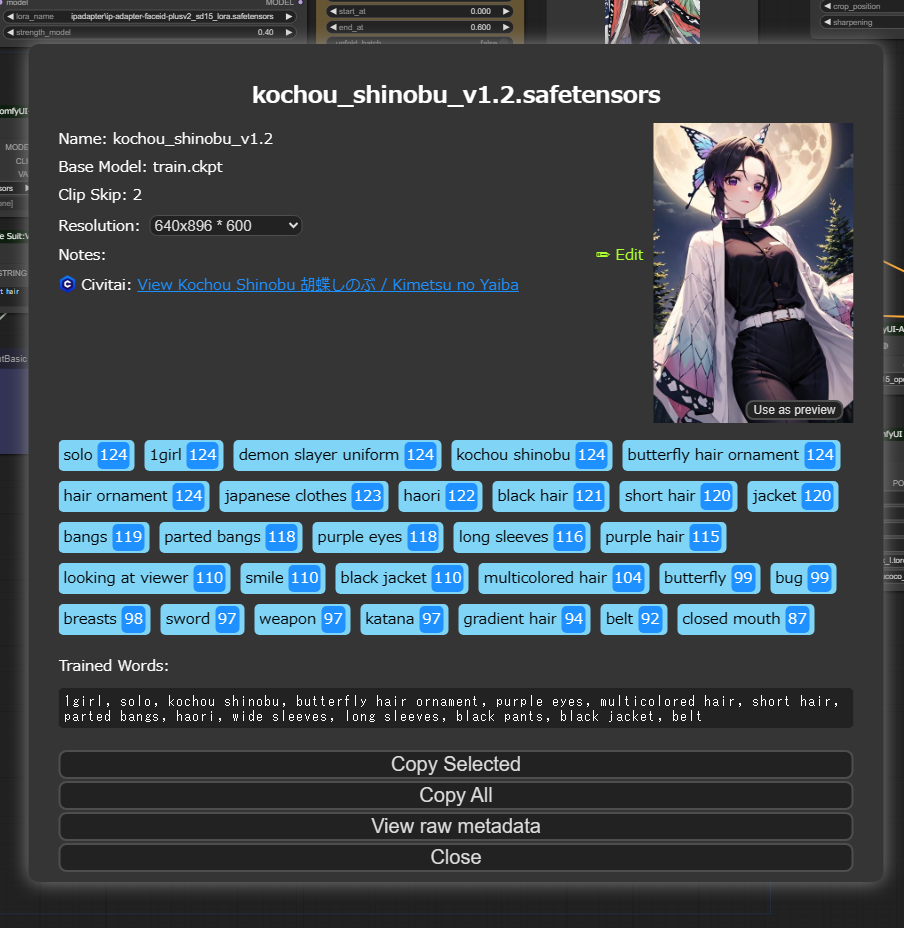
LORAの情報を表示してトリガーワードの確認とcheckpointモデルを変更します。
プロンプトの記入に役立つ Joytag Node
プロンプトの記載は重要ですが面倒な作業でもあります、イメージから生成する場合はイメージからタグを読み込めばその分、短縮することが出来ます、そこでVLM_nodes の Joytag Nodeを利用して最小限の記載で済むようにしていきます。
Custom NodesからVLM_nodesをインストールすると使用可能になります。VLM_nodesには画像の詳細な説明と音楽生成の機能がありますが、これらは非常にリソースを消費するため、VRAMが不足する可能性があるため使用は推奨されません。
画像を詳細に説明する機能を利用するためには、llava-1.5-7b-Q4_K.ggufとlava-1.5-7b-mmproj-Q4_0.ggufが必要です。
jartine/llava-v1.5-7B-GGUF at main (huggingface.co)こちらのサイトからダウンロードしてご使用ください。
Joytag Nodeの使い方は Load Image → Joytag Node→ TextInputBasic→Show Text 🐍 と CLIP Text Encode (Prompt)に 繋ぎます。
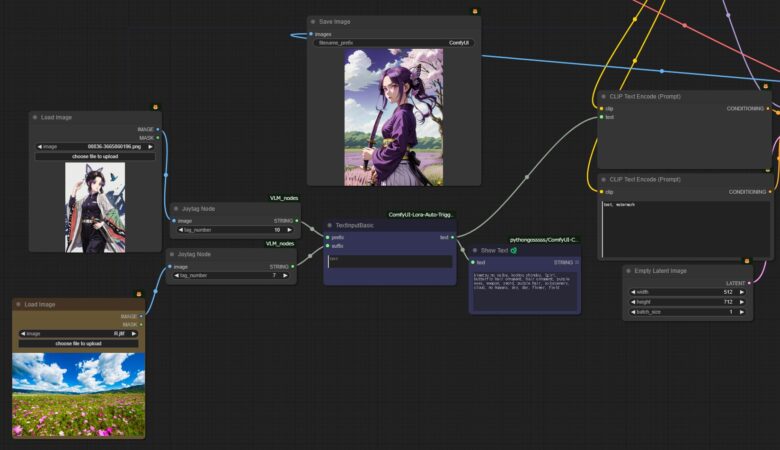
キャラクターと背景のタグは自動で追加されるようになりました。追加の記述が必要な場合は、TextInputBasicに入力してください。
生成された画像を見てみましょう。
LORA無しでもある程度類似した画像が生成されています。


衣装の固定
衣装が必ず固定されるわけではありませんが、ある程度の固定は可能です。そのためには、イメージ画像からマスク画像を作成し、人物を切り抜いてMODELラインにデータを埋め込みます。
マスクで人物を切り取るには、GroundingDinoSAMSegment(segment anything)を使用します。ノード名は「segment anything」で、Custom Nodesからインストールして使用してください。
GroundingDinoSAMSegment(segment anything)につながるSAMModelLoader (segment anything)とGroundingDinoModelLoader (segment anything)はラインを伸ばすと候補に出てくるので選択するだけです。
カスク範囲は human(人)や clothing(衣装)を指定します。
上手く切りとれない場合は thresholdの設定値を上げて切り取ってください。
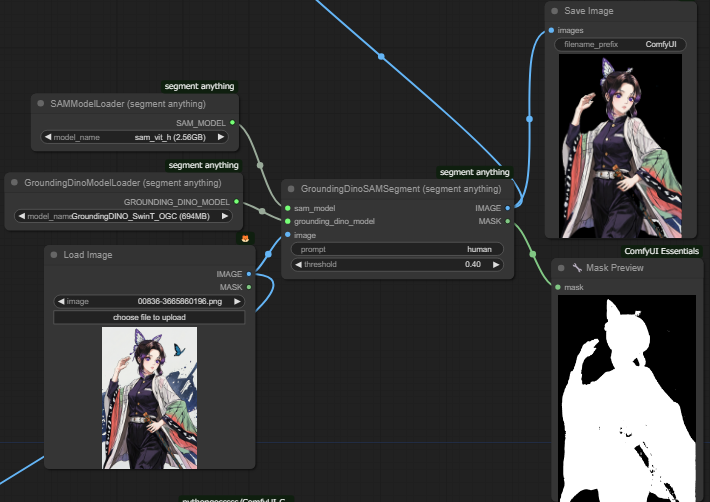
次に、このイメージをモデルラインに割り込ませていきます。
Prepare Image For Clip Vision にイメージを繋ぎ Apply IPAdapterにとりこみます。
Load IPAdapter Model と Load CLIP Visionを繋ぎ それぞれのfileをインストール して選択します。Custom Nodesからインストール出来ます。
モデルラインは KSampler 繋がっているラインを Apply IPAdapterに繋ぎなおして、出力側のモデルラインをKSamplerに戻します。
IPAdapterのweight設定を0.4~0.6の範囲に調整すると背景がぼやけず、キャラクターも適切に生成されます。また、noiseを0.2~0.4程度に保つと衣装が意図せず変わることを防げます。
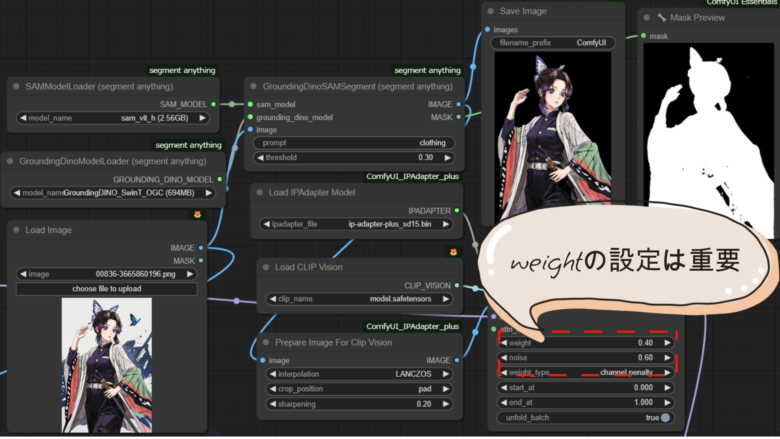
アニメーションにすると衣服の変化は目立ちますので、出来るだけ変化しない様にしておきます。






背景イメージの追加
使用されたプロントは
「鬼滅の刃、胡長しのぶ、1女の子、蝶の髪飾り、髪飾り、紫の目、武器、剣、紫の髪、ソロ、バグ、ベルト、羽織、色とりどりの髪、蝶風景、雲、人間なし、空、日、花、フィールド、屋外、青空、花畑」
でしたが、背景に意図しない円形の模様が現れました。LORAの設定を調整しても解決できなかったため、背景画像を直接取り込んで表示することにします。
背景の取り込みにはイメージを Prepare Image For Clip Visioで受け取り Apply IPAdapterにとりこみます。 後は 衣装の固定と同じです。
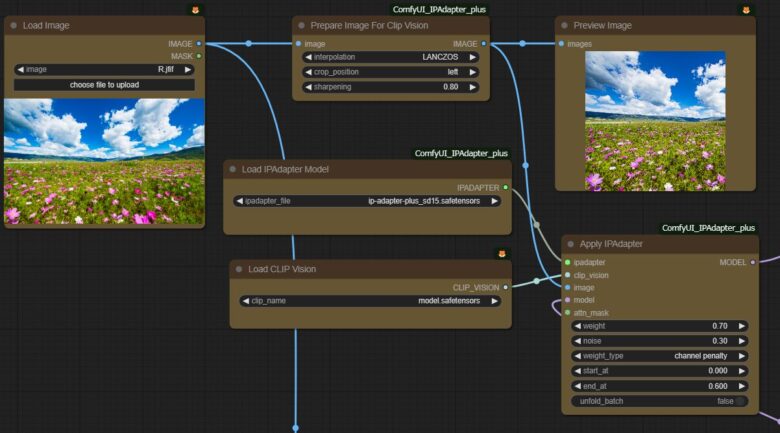
モデルラインはLORAから出力されたものを背景のApply IPAdapterへ 入れて 出力を衣装の固定側のApply IPAdapterに戻します。






背景が取り込まれ、表示されるようになりました。
LoraLoaderModelOnly の追加
LoraLoaderModelOnlyはキャラクター生成の結果を変更します。使用するには、MODELラインに統合し、設定値を1に設定することで、全身画像からズームインした画像に切り替えることができます。
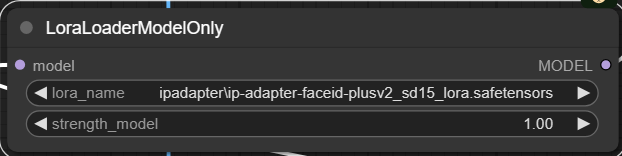


コントロールネットでポージングする場合には、あまり意味がないため、使用するかどうかは状況次第です。
ポージング 「ControlNet」
イメージ画像からポーズを呼び込み、キャラクターに適用していきます。
使用する openpose を組み込んでいきます。
最初に Apply ControlNet (Advanced) をプロぷとラインに割り込ませます。
Load Advanced ControlNet Model 🛂🅐🅒🅝 と DWPose Estimator を繋ぎ Load Imageで画像を取り込みます。
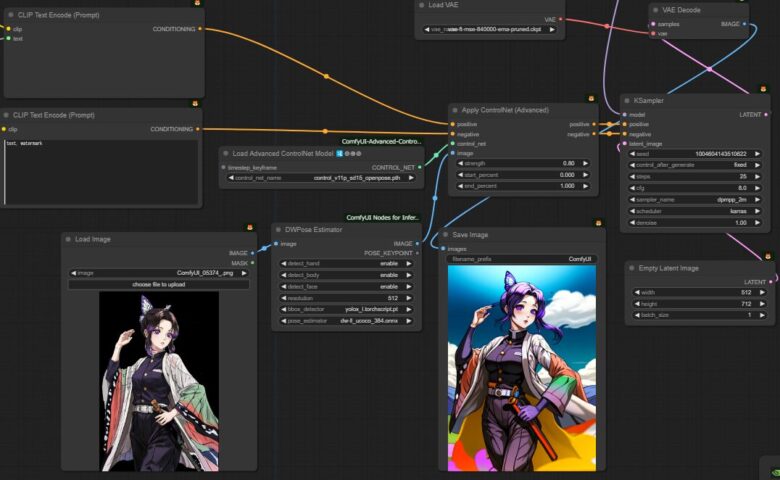
OpenPoseを使用してポージングは可能でしたが、アニメーション化する際に重なった手足が入れ替わることがあります。これは、OpenPoseが左右の手足のどちらが前にあるかを判別できないためのようです。
この現象を和らげる為に、もう一つコントロールネットを追加しておきます。
色々なタイプが用意されていますがここでは tileを使用する事にしました。
取り付け方法はOpenPoseと同様ですので、詳細は省略しますが、strengthは低めに設定します。
アニメーション化しない場合、この設定を省略しても構いません。
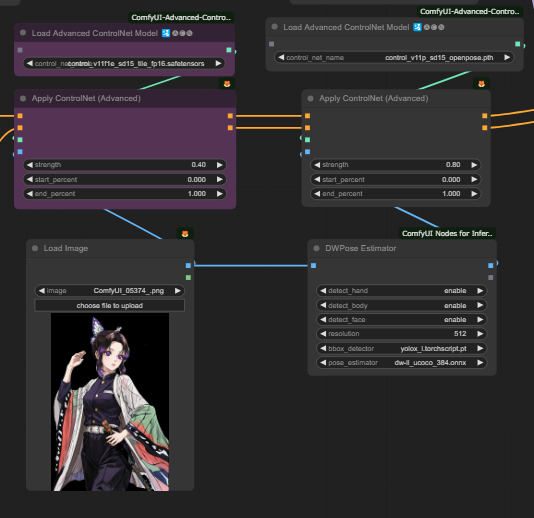
生成される画像には特に変化は有りませんがアニメーションにすれば違いが出てきます。
予告
次回はアニメーションノードを組んでいきます。
YouTube動画 の元動画を生成していきます。