DreamArtist-sd-webui-extensionの利用例とその効果の評価


- 1. 「DreamArtist」とは?
- 2. 「DreamArtist」のインストール
- 3. 「DreamArtist」の設定
- 4. 🏳Embeddingを作成
- 5. 🏳「ドリームアーティストのトレーニングを行う」
- 6. モデルリンク
- 6.1. Embedding
- 6.2. Embeddingの学習率(Learning rate)
- 6.3. DreamArtist
- 6.4. CFGスケール (動的 cfg: low,high:type 例: 1.0-3.5:cos)
- 6.5. 再構築 損失の重み・ネガティブ学習率の重み
- 6.6. 分類モデルのパス
- 6.7. バッチサイズ と 回数
- 6.8. データセットディレクトリ
- 6.9. ログディレクトリ ・プロンプトテンプレートファイル
- 6.10. ポジティブ「ファイルワード」のみ
- 6.11. 幅と高さ
- 6.12. 🏳最大ステップ数
- 6.13. 🏳指定したステップ数ごとに画像を生成し、ログに保存する。0で無効化
- 6.14. 🏳指定したステップ数ごとにEmbeddingのコピーをログに保存する。0で無効化。
- 6.15. 保存する画像にembeddingを埋め込む
- 6.16. 🏳プレビューの作成にtxt2imgタブから読み込んだパラメータ(プロンプトなど)を使う
- 6.17. 実験的な機能(不安定なトレーニングや再現性の低い問題を解決する可能性があります。[EMAを0.97に設定])
- 6.18. 🏳学習の実行
- 7. 学習結果
- 8. Att-Mapの処理を行う
「DreamArtist」とは?
DreamArtistはたった1つのトレーニング画像で、コンテンツとスタイルを学習し、高い制御性を備えた多様で高品質の画像を生成します。 DreamArtistの基本的な操作方法を紹介します。
設定変更個所に🏳マークを立てています、一応、各項目の説明を入れていますが飛ばしていただいても問題は有りません。
「DreamArtist」のインストール
「DreamArtist」はStable Diffusion WebUIの拡張機能ですので拡張機能タブからインストールができます。
「拡張機能タブ」を開き、「拡張機能リスト」タブの「読み込みボタン」を押してリストを表示させます、検索に「DreamArtist」と入力、又はコピペすると「DreamArtist」のみが表示されますのでインストールして下さい。
設定タブに戻り UIの再読み込みを行うと「DreamArtist」タブが表示される様になります。

「DreamArtist」の設定
「DreamArtist」タブを開くと「ドリームアーティスト埋め込み作成」・ 「ドリームアーティストのトレーニングを行う」・ 「Att-Mapの処理を行う」の3個のタブが表示されます。
🏳「ドリームアーティスト埋め込み作成」
今回学習させるキャラクターは「江戸前エルフ」のキャラクターを学習させます。
画像は1縦横1:1の画像をネットから拾ってフォルダーに保管します。

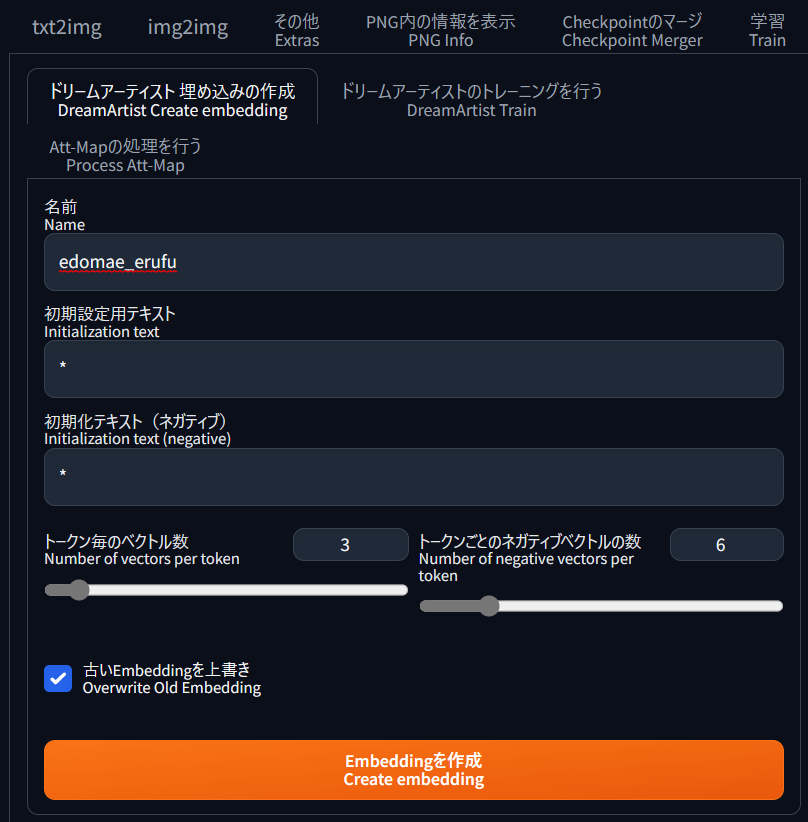
🏳名前
学習させる画像の名前を入力します、ここに記載した名前が画像生成時のトリガーワードになります。ここでは「edomae_erufu」とします。
初期設定用テキスト
ここの記載は不要です。書くとすれば「woman」や「girl」などを入れます。
※プレビュー表示などは「txt2img」のプロンプトが使用されますので「*」のままで機能します。
初期設定用テキスト(ネガティブ)
ここの記載は不要です。書くとすれば「Undressing」や「Unwanted limbs」などを入れます。
※プレビュー表示などは「txt2img」のネガティブ・プロンプトが使用されますので「*」のままで機能します。
トークン毎のベクトル数 ・ネガティブベクトル数
埋め込みのサイズを表しています。この値が大きいほど、埋め込みに関する情報が多くなります、トークン毎のベクトル数は変更する必要性は有りませんが、ネガティブベクトル数は学習が上手くできない場合は少し上げても良いかもしれません。
古いEmbeddingを上書き
再設定を行う場合はチェックを入れる、通常は誤設定を避ける為、チェックを外しておきます。
🏳Embeddingを作成
Embeddingを作成ボタンを押すとファイルが作成され「txt2img」の「Textual Inversion」に保存されます。
これを使いプレビューで表示される画像用のプロンプトを書いて行きます
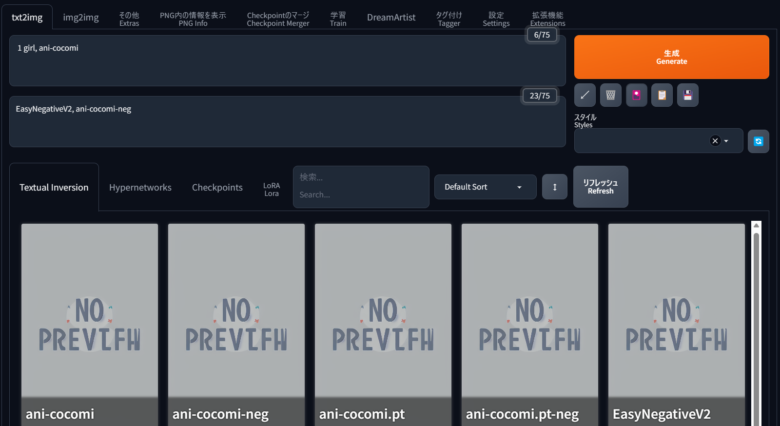
正プロンプト ➡️ 1 girl・1 man ・ woman などの後に Textual Inversionタブに表示された名前をクリックして 「1 girl 、〇〇〇」と記載します、プロントは何でも良いが登録したトリガーワード(名前)を必ず入れる様にしてください。 例:1 girl,edomae_erufu
ネガティブプロント ➡️ Textual Inversionタブからトリガーワード(名前)+「-neg」をクリックして挿入してください、後は追記が有れば追記して終了です。
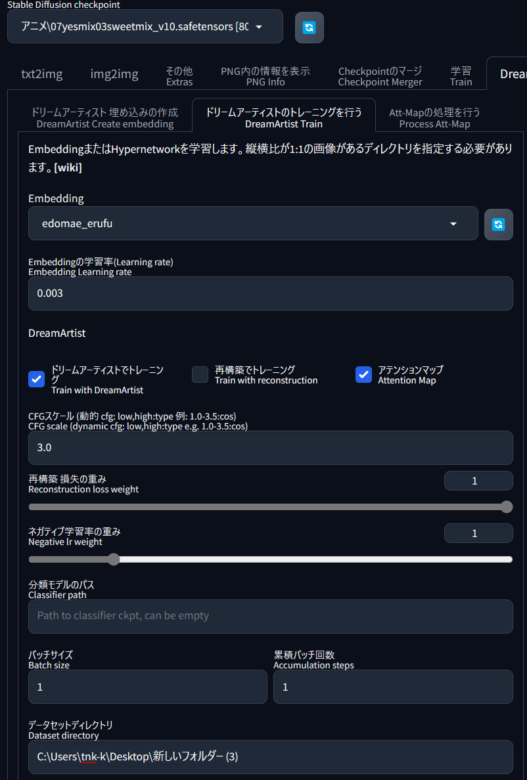
🏳「ドリームアーティストのトレーニングを行う」
トレーニングを開始する前に使用モデルを選んでいただきます、推奨されているモデルは5つ、それぞれのリンクを準備しましたので学習素材に有ったモデルを選んでダウンロードしてください。
ダウンロードファイルは「stable-diffusion-webui➡️models➡️Stable-diffusion」の中に入れて使用します。
推奨されている使用モデル
各モデルを「1 girl」で生成した参考画像になります、アニメ風の画像は animefull-latest ・momoko-e 。 ドール・リアルよりの画像は Anything v3.0。 実写画像はSD v1.4・ SD v1.5を使用します。

モデルリンク
アニメ画像 ➡️ animefull-latest ・momoko-e
肖像画 ➡️ Anything v3.0
写真 ➡️ SD v1.4・ SD v1.5
- animefull-latest
- Anything v3.0
- momoko-e
- SD v1.4
- SD v1.5
これらのモデルを「Stable Diffusion checkpoint」に指定してから各設定を行っていきます。
Embedding
更新ボタンを押して、ダウンリストから埋め込みの制作した名前「edomae_erufu」を選択します。「edomae_erufu-neg」ファイルはネガティブ学習ファイルですのでここで選択するとエラーになるので選択出来ません。
Embeddingの学習率(Learning rate)
「Embedding Learning rate」とは、学習の深度を決める数字で、高くすると埋め込みファイルが機能しなくなったり、プロンプトに従いにくくなったりする可能性がありますので、このままの設定0.003で行います。
DreamArtist
「ドリームアーティストでトレーニング」・ 「再構築でトレーニング」・「アテンションマップ」のチェックリストの中で「再構築でトレーニング」だけはデフォルトでチェックが外されています。
「再構築でトレーニング」は入力データを再構築するためにモデルをトレーニングするプロセスを指しますので、デフォルト設定のままにしておきます。
CFGスケール (動的 cfg: low,high:type 例: 1.0-3.5:cos)
Stable Diffusionの画像生成時のデフォルト設定は(7)ですが「DreamArtist」のデフォルト設定は(3.0)と低く設定してあります、設定値3.0はプロントが無視されないギリギリの値でも有り、最も処理速度が速い設定でもあります。
8000回以上繰り返される学習の工程では処理速度の違いで数時間のロスが生じてしまいますのでここでは欲張らず3.0~5.0までに留める様にします。
動的 CFG とは、特にデータ・セットが大きい (>20) 場合に、パフォーマンスを向上させます。 たとえば、1.5 から 3.0 (1.5-3.0) までの直線的な場合、またはコサインの 0-π/2 サイクル (1.5-3.0:cos)、コサインの -π/2-0 サイクル (1.5-3.0:cos2) などです。 または、2.5-3.5:torch.sqrt(rate) のように、rate が 0-1 の変数である非線形関数をカスタマイズすることもできます。
再構築 損失の重み・ネガティブ学習率の重み
再構築では無いので「再構築 損失の重み」は設定不要な項目です。
「ネガティブ学習率の重み」は学習に関係する項目では有りますが上げると若干ですが速度が遅くなる様に感じます、時間のロスは避けたいので設定1のままで行います。
分類モデルのパス
ここには推奨モデルもパスを記載しますが、薄い文字で書かれている様に 空白にする事も出来ます。プレビュー表示されませんので敢えて記載する必要は有りません。
バッチサイズ と 回数
数値を上げると処理速度が倍に増加しますが 設定値1でもVRAMの90%以上を使用していますので数値を上げるとエラーで止まります。 RTX 3080Ti 以上のグラボをお持ちの方は動くかもしれませんので試してください。
データセットディレクトリ
学習させる元画像の保管フォルダーパスを記載します。
ログディレクトリ ・プロンプトテンプレートファイル
変更不可 自動でパスが記載されます。
ポジティブ「ファイルワード」のみ
ネガティブファイルを無視する設定です、特に変更する必要はありません
幅と高さ
この数値を触ってもプレビューの表示サイズは変わりません、学習範囲が拡張される様で数値を上げるとGPUの使用率が極端の上昇してPCが落ちますので 触らない方が無難です。
🏳最大ステップ数
学習を何回繰り返すかの設定 です、デフォルト値は8000回ですが プレビュー表示で似ていなければ回数を増やして追加学習させることが出来ます。
🏳指定したステップ数ごとに画像を生成し、ログに保存する。0で無効化
そのままの意味です。無駄な画像が大量に生成されますので1000単位での設定を推奨します。
🏳指定したステップ数ごとにEmbeddingのコピーをログに保存する。0で無効化。
最初に設定したEmbeddingの保存の頻度を指定します。以下同上
保存する画像にembeddingを埋め込む
画像の保管場所は「stable-diffusion-webui➡️dream_artist➡️日付(2023-08-17)➡️名前(edomae_erufu)➡️image_embeddings
下図のように画像にembeddingの情報が埋め込まれます、必要ならチェックを入れます。
🏳プレビューの作成にtxt2imgタブから読み込んだパラメータ(プロンプトなど)を使う

Embeddingを作成で記載した,プロンプトを使いプレビュー表示するかの設定です。
ここは必ずチェックを入れる様にして下さい。
実験的な機能(不安定なトレーニングや再現性の低い問題を解決する可能性があります。[EMAを0.97に設定])
これより下は実験的機能だと書かれていますのでこのまま触らずに飛ばします。
🏳学習の実行
「Train Embedding DA」ボタンを押して学習スタートです。
8000回の学習にはPCスペック因りますが1時間程度は掛かりますので気長にお待ちください。
学習結果
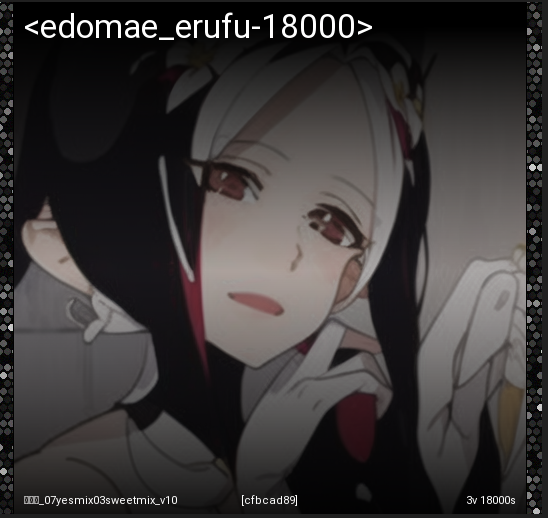
8000回では学習不足を感じましたので追加学習8000回を追加して、 合計16000回の学習を行いました。
その学習結果がこちらです、 キャラクターの特徴を良く学習している事が見て取れます。






Att-Mapの処理を行う
アテンションマスクは、一部の地域の学習強度を強化または弱めることができます。 アテンションマスクは、グレースケール値が次の表に示す学習強度に関連するグレースケール画像です。

| グレースケール | 0% | 25% | 50% | 75% | 100% |
|---|---|---|---|---|---|
| 強度 | 0% | 50% | 100% | 300% | 500% |
アテンションマスクをトレーニング画像と同じフォルダに入れます、名前にはトレーニング画像名の後に「_att」を追加します。 トレーニングでアテンションマスクを有効にするかどうかを選択できる様になります。