【超初心者用】LoRA学習起動パッチを使用した学習環境のセットアップ方法

前書き
この記事では、LoRaのインストールと設定・起動方法を順に説明していきます。
この記事内で紹介する実行バッチは以前YouTubeでも紹介されていた超初心者用LoRA学習起動パッチの最新版を使用していますので初心者の方でも簡単に設定出来るような内容にしています、LoRa学習は初めての方にとっては少し複雑に感じるかもしれませんがこのガイドに沿って進めれば、あなたもLoRaを使って独自モデルを開発出来るようになります。
さあ、LoRaの世界へ一歩踏み出しましょう。

準備はできましたか?それでは、始めましょう!
まずはPC環境を確認してみましょう。
VRAM塔載量でセッティング数値が変わりますので重要な要素となります。

必要なハードウェアとソフトウェア
PC構成
Stable Diffusionをローカル環境で使えているなら問題はありませんがGoogle Colabを利用している方は注意が必要です、最低限必要なPCスペックは次の通りです。
- GPU NVIDIA製のグラフィックボード8GB以上 (6GBでも動くが不安定)
- CPU Windows 10が動けば特に問題なし
- メモリー 32GBあれば十分
- メインストレージ 2T以上 画像保管を別のHDDかSSDに振り分ければ1Tでも良い。
ハイエンドの GeForce RTX4090 24GB の性能には憧れますが、さすがに手が届きません。
僕が今、買えるのは一世代前のRTX3060Tiだけど、どうせならRTX4060Tiだよね!



グラフィックボードはとても高価なPCパーツよ!
ハイエンドモデルに拘らないでお財布と相談してね!
Windows環境で必要なプログラム
Stable Diffusionのインストールでも使ったPython 3.10.6およびGitが今回も必要になります。エラーが出る場合は最インストールしてください。
- パイソン 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
- ギット: https://git-scm.com/download/win
LoRaのインストール方法
インストールは手動で行う方法と自動で行う方法が有りますが今回はinstallers v6を使って行きます。
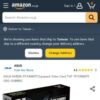
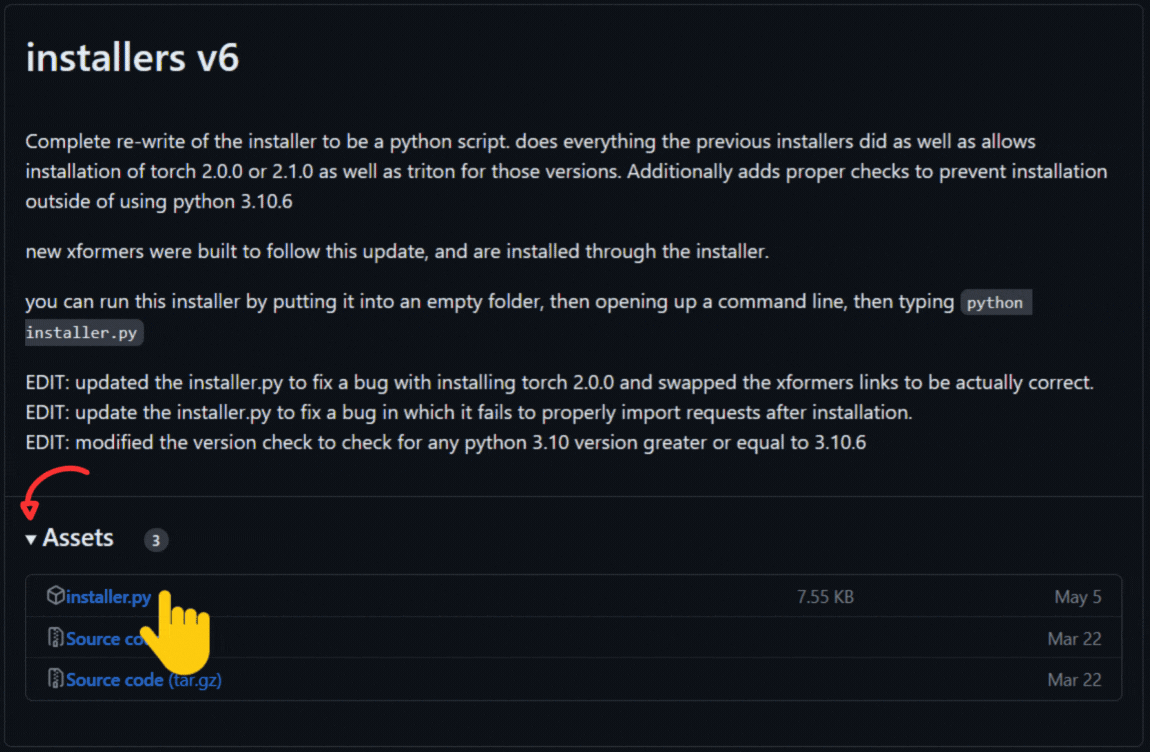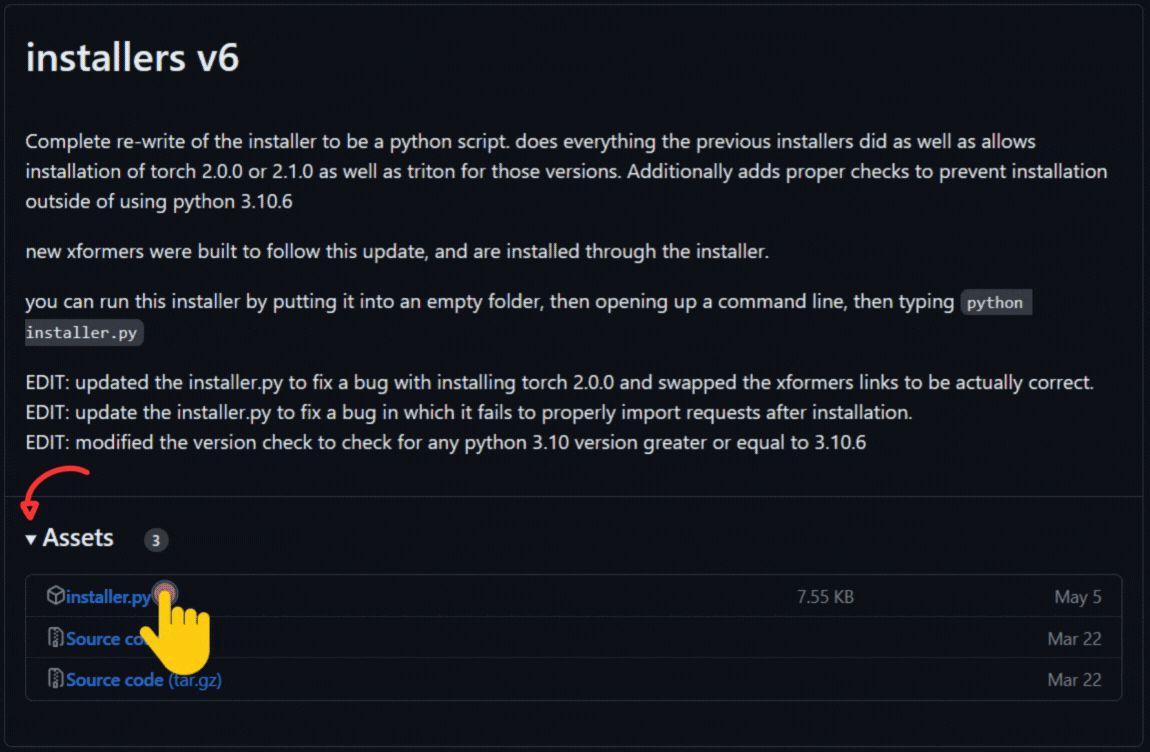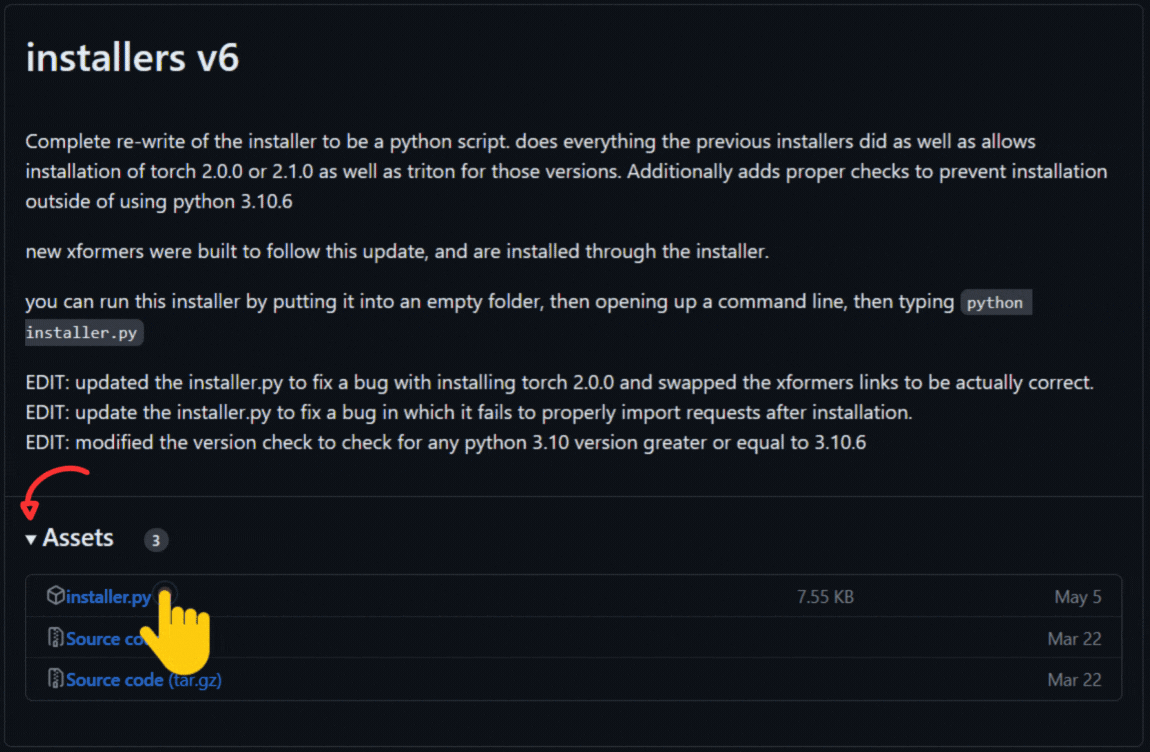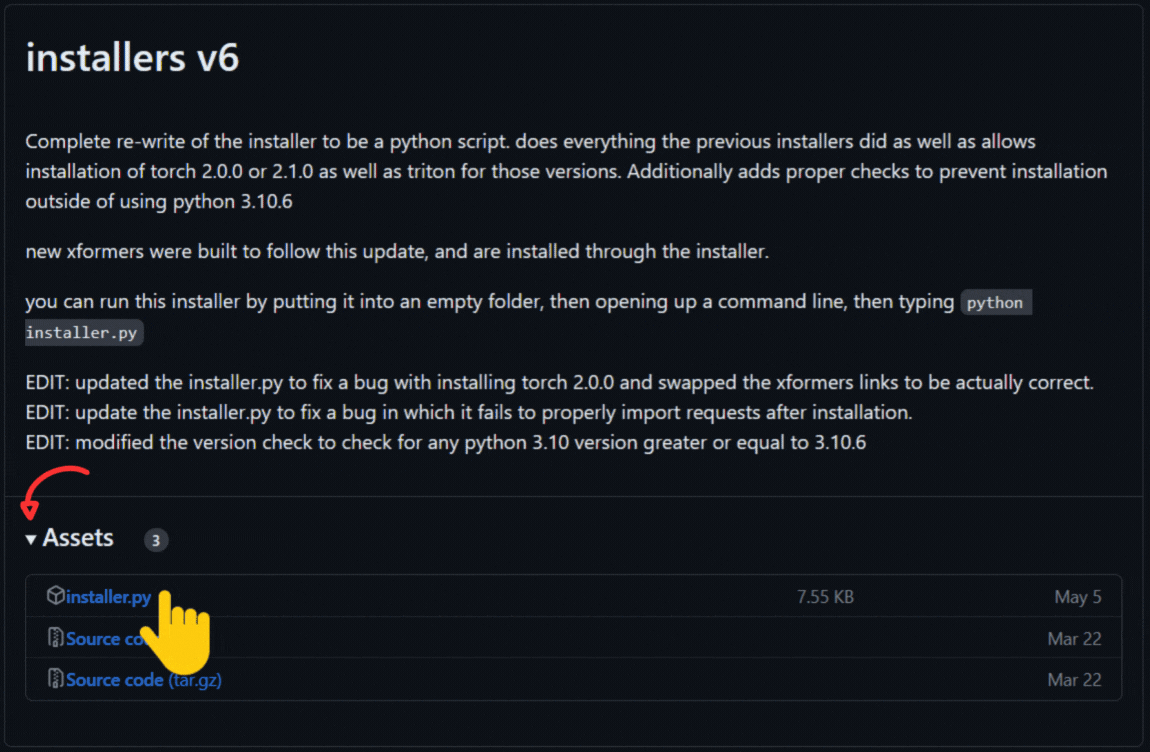
配布サイトに行ってinstaller,pyを入手してください。
installers v6はReleases · derrian-distro/LoRA_Easy_Training_Scripts (github.com)で入手することが出来ますのでサイトに移動してください。
installers v6でのインストール
- ダウンロード
- installers v6の「▼Assets ❸」を押して添付ファイル一覧を開く
- 「installers.py」をクリックしてダウンロードする
- ダウンロードファイルの保存
- 新しいフォルダを作成し日本語を含まない名前に変更してダウンロードファイルを入る
- ファイルの保管場所を日本語を含まない場所に変更する
- ファイルの中の「installer」をクリックする。(パイソンがファイルをダウンロード)
- 新しく「LoRA_Easy_Training_Scripts」と言うフォルダーが作られる
venv の作成と要件のインストール
「LoRA_Easy_Training_Scripts」の中に「install」と言うWindowsバッチファイルがあります、クリックしてvenv の作成と要件を入力していきます。
準備はできましたか?それでは、始めましょう!
選択項目は3点のみです!
最初の問1⃣
Running on windows…
Python version 3.10 detected…
Git is installed… installing
setting execution policy to unrestricted
creating venv and installing requirements
which version of torch do you want to install?
0 = 1.12.1
1 = 2.0.0
2 = 2.0.1:
どのバージョンをインストールしますかと聞かれています。
今回は(2.0.1)を選択しする事にするよ💞
数字の(2)を入力してね!
問2⃣
しばらくすると「Do you want to install the triton built for torch 2? (y/n): 」と質問されます。
torch 2とは機械学習フレームワーク「PyTorch」の新版「PyTorch 2.0」を使うか聞いています。
処理速度が向上するみたいよ!
「y/n:y」を入力して Enntaを押してね!
問3⃣
更に、しばらくすると「Do you want to install the optional cudnn patch for faster training on high end 30X0 and 40X0 cards? (y/n):」と質問されます。
ハイエンドモデルのビデオボード を使って高速でトレーニングをしますか?と聞いています。
これは PCスペックで変わるわね!
グラフィックボードが3000番以上なら
yesu、それ以外ならNoにしてね!
Enntaをクリックすると「続行するには何かキーを押してください」と出ますのでキーを押して終了です。
これでLORAのインストールは完了しました、次に設定を行います。
コマンドの設定
コマンドの設定は難解ですので色々飛ばします。
まずは、以下のファイルをダウンロードしてください。
ややこしいのでまとめてみました。文字化けしてたらごめんなさい(>_<)
ファイルセットのダウンロード
ダウンロードファイルはデスクトップ等に新しいフォルダを作り保管と解凍を行って下さい。
中身は「lora_data」と「Learning_settings」の2点です。
この2つのファイルを「LoRA_Easy_Training_Scripts」と同じフォルダに入れます。
保管・解凍に使ったフォルダは不要ですので消去して下さい。
コマンド設定
まずは、Learning_settingsを編集します。
「rem」はコメントですので無視してください。
かなりの長文ですが、大半は解説文で、編集量は見た目ほど多くはありません。
- メモ帳アプリを立ち上げます。
- Windowsロゴ横の検索バーの「メモ」と入力するとでてきます。
- 「Learning_settings」をメモ帳の上にドラッグ&ドロップします。
- 中身が表示されますので設定をする。
ベースモデルの設定
ファイルパスの入力はモデルパスとVEAパスの2ヶ所と出力画像のファイル名のみです。
他の4ヶ所のパス設定は同じフォルダの各フォルダに設定されていますので今回は変更する必要はありません。
em ----ここから自分の環境に合わせて書き換える----------------------------------
rem sd-scriptsの場所
set sd_path="%cd%\LoRA_Easy_Training_Scripts\sd_scripts"
rem 学習のベースモデルファイル
rem fp32よりもfp16の方が消費VRAMを抑えられるので推奨
set ckpt_file=""
rem 学習のベースVAE(必須ではないので使用しない場合は--vae=...の行を削除)
set vae_file=""
rem 学習画像フォルダ このフォルダ内に10_AAAなどのフォルダが入っていること
set image_path="%cd%\lora_data\sozai"
rem 正則化画像フォルダ(必須ではないので使用しない場合は reg_path="" とすること)
set reg_path="%cd%\lora_data\seisoku"
rem set reg_path="%cd%\lora_data\seisoku"
rem メタデータjsonファイル(このファイルを指定するとファインチューン動作になり、json_file="" で従来のDBになる)
set json_file=""
rem set json_file="X:\data\marge_clean.json"
rem ファインチューンでのリピート数を指定 DBでのフォルダ名の数字は無視される
set ft_repeats=1
rem データセットファイル(json,toml形式)
rem(このファイルを指定するとデータセットモード動作になる。使用しない場合は""とすること)
set dataset_file=""
rem 学習結果の出力先
set output_path="%cd%\lora_data\output"
rem 学習結果のファイル名
set file_prefix="test"ベースになるモデルを指定してね!
今回は「7th_anime_v3_A」を使います。
この他にも学習に向いているモデルとしてACertaintyやanything-v3-1やHD-17が良いと言われているよ。
パスを書くのは面倒だからパスをコピーする方法を書いとくね!
stable-diffusion-webuiのフォルダを開きmodels→Stable-diffusion→モデルファイルが見える所まで進みます。
目的のモデル「7th_anime_v3_A」を選択(シングルクリック)してから右クリックして
パスのコピーをクリック。
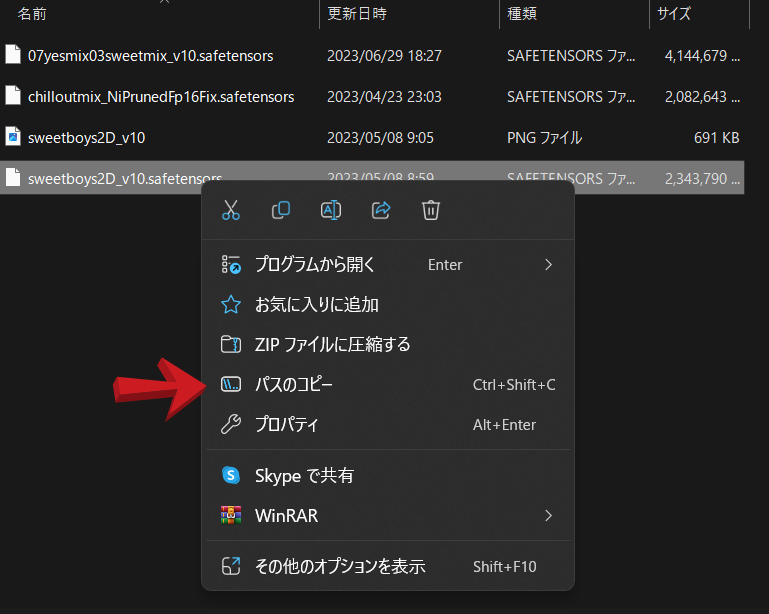
セッティング画面の戻り「set ckpt_file=""」の””部分を上書きする様に選択し貼り付けます、くれぐれも””が重複しないようにご注意ください。
例:set ckpt_file="D:\stable-diffusion-webui\models\Stable-diffusion\sweetboys2D_v10.safetensors"
VEAパス設定も同等に行ってください場所は以下の通りです。
stable-diffusion-webuiのフォルダを開きmodels→VEA→ファイル
VAEを使用しない場合は行ごと消去するか、頭に「rem」を入力して読み込まないようにして下さい。
パスには日本語表記が無い様に御注意ください。
学習画像ファイル名はstable-diffusionで表示される名前です、ローマ字で好きな名前を書いてね!
ここでは「zko」とします。
パラメーター設定
パラメーターの数値変更が必要な所はepoch数と何epochごとに保存するかの設定です。 epoch数を大きくすれば学習回数も増えていきます。保管設定は何学習回数毎に保管するかの設定です。細かな説明はデーターの中に書かれていますので良く読んでください。
set num_epochs=3 3回では学習不足です、本番では数値を上げてください、学習ステップ数は繰り返し回数 × 学習用画像の枚数 x epoch数です。
今回準備したサンプルデーターは61枚あります
繰り返し10回×学習画像61枚×epoch数 10回で学習ステップは6100回 2時間30分の工程になります。
何処まで学習すればベストな結果になるのかが分かっていませんのが、時間短縮をする場合は学習画像回数を減らしてください。
set save_every_n_epochs=1 : 学習ステップ数が多すぎると過学習になり、以後は絵が崩壊していきます、毎回保管する必要はありませんが少な過ぎると残念な結果となりますのでご注意を!
rem 学習パラメータ
set learning_rate=1e-3
rem 学習開始時にlearning_rateが指定値に到達するまでのステップ数 デフォルトは0
set lr_warmup=0
rem 個別の学習パラメータ デフォルトにしたい場合は全て上のlearning_rateと同じ値にする
set text_encoder_lr=1.5e-4
set unet_lr=1.5e-3
rem epoch数と何epochごとに保存するかの設定 1epoch=全フォルダの(画像数xループ数)の合計
set num_epochs=3
set save_every_n_epochs=1
rem スケジューラー 以下の文字列から選択: linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup
rem どれがベストかは要検証
set scheduler="cosine_with_restarts"
rem cosine_with_restartsのリスタート回数 デフォルトは1
set scheduler_option=1システム設定
ここの設定はPCスペックに合わせて変更してください。
CPUスレッド数を大きくし過ぎるとメモリー不足で止まります、実際のコア数より少なくするといいよ!
バッチサイズ: VRAM 12GB塔載のPCで3が限界です、余裕を見て2まで下げています。タスクマネージャーで使用状況を見ながら変更してください。
=========================================================================
rem VRAMなど環境に影響されるパラメーター 余裕があれば増やすと速度や精度が改善
rem CPUスレッド数 CPUのコア数がいいらしい
rem 増やすと生成速度が上がる代わりにメインメモリの消費が増えるので
rem メモリ32GBの人はCPUのコア数よりも減らした方が安定するかも
set cpu_thread=8
rem データローダーのワーカー数
rem デフォルトは8、減らすとメインメモリの使用量が減り、学習時間が増加
set workers=8
rem バッチサイズ: 増やすと計算が早く終わるがVRAM消費が増える
set train_batch_size=2
rem 学習素材の解像度: 大きくすると細部まで学習するが消費VRAMが増える
rem VRAM12GBなら768くらいまで増やせる
set resolution=512,512
rem 最小、最大バケットサイズ: 画像が正方形でなくてもresolutionの面積を超えない範囲で
rem 縦長、横長の画像も扱えるのでresolutionを増やしたらmax_bucketも合わせて増やすといい
set min_bucket=320
set max_bucket=1024
rem 学習の改善に有効?
rem 詳細はsd-scriptsのgithubを参照
rem 推奨値は5
set min_snr_gamma=5お疲れ様でした設定はこれで終わりです。
上書き保管して閉じてくださいね💞。
作動テスト
ダウンロードファイルの中にlora_dataと言うフォルダが入っています。それを開くと学習済みファイルのフォルダ「output」・正則化画像用のフォルダ「seisoku」・学習元画像のフォルダ「sozai」の3個のフォルダを用意しています。
「sozai」フォルダにはサンプルデータを61個ほど入れて有りますので 本番ならそのままで、起動確認だけならファイルを消して10個程度にしてください。ファイル名は1から連番にする必要がありますので下から順に消去してください。
じゃ!行くよ
Learning_settingsをダブルクリック!・・・?
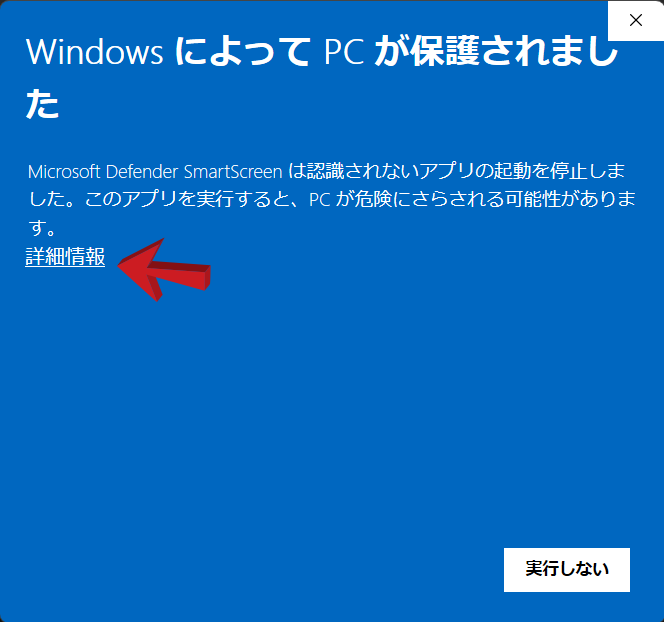
初回の立ち上げ時にはセキュルティーで止められてしまいます。
明細情報をクリックすると実行ボタンが現れますので実行を押してください。
パスエラー等が出なければ成功です。
パスエラーが出た場合→ パスの中に日本語表記が無いか確認・””が重複していないか確認してください。
“RuntimeError: CUDA out of memory."とエラーが出て途中で止まった場合はGPUのVRAM不足です→set workers=4に変更してください。
ページングファイルが足りないとエラーが出て途中で止まった場合は仮想メモリーが足りていません、Windowsの設定->システム->詳細情報->システムの詳細設定->パフォーマンス[設定]->仮想メモリ[変更]で1.5倍程度、増やしてください。
stable-diffusion-webuiで使って見る
stable-diffusion-webuiのLoRAの入ったフォルダに学習済みファイルを入れます。
パス例 x:/stable-diffusion-webui/models/Loraの中に"zko.safetensors
stable-diffusion-webuiを起動さて🎴→LoRAタブを開きます、リフレッシュボタンを押して更新するとzkoが表示されます。
今回、学習した画像はこちら。



よく知りませんが音声ソフトのキャラクターだとか?
そして、こちらがLoRAで生成した画像です。

似てないわね!
よく見て! 髪型が違うので似ていない様に見えるけど顔の輪郭などは同じでしょ、学習したのは顔だけだから髪の色や髪型はプロンプト呪文で変えられる様になっているんだ。
髪の色や髪型、瞳の色なども一緒に学習すれば制度は上がるけど自由度は下がってしまうんだよ。
髪の色が上手く出せないので苦戦しましたがプロンプトを入れた画像がこちらです。
トリガーワードの「Zunko」だけでキャラは生成されますので瞳の色と髪を学習させて<lora:zko_kami :1>を最後に挿入してあります、ですが結局は髪色は出力されていません。
Zunko, 1girl, Solo, < Blue Hair:0.3>5dark green hair, Shiny hair,smiling face,Green Hair Band, Long Hair, Full Body, Very Long Hair, White Background, Simple Background, Hair Band, Standing, Ponytail, High Ponytail, Bangs, Green Jacket, Socks, Side Lock, Jacket, Look at Viewer,Smile, Long Sleeves, Pants, Tracksuit, Hands Up, Yellow Eyes, Blush, Green Pants, Mouth Closed, Alternative hairstyles, sleeves past wrists, track pants, no shoes <lora:zko_kami :1>


まだ、微妙かな?
更に学習時間を倍にして再チャレンジしてみました。
結果としては差ほど変化は有りません。瞳の色や髪の色のグラテーションが上手く表現できない様です。

zunko,1girl, aqua hair, bangs, barefoot, closed mouth, eyebrows visible through hair, full body, green hair, green kimono, hair scrunchie, hairband, japanese clothes, kimono, long hair, long sleeves, looking at viewer, obi, ponytail, print kimono, sash, scrunchie, simple background, sitting, smile, solo, very long hair, white background, wide sleeves, yokozuwari, yukata





まとめ
出来るだけ簡単に動かせるようにはしたつもりですがLoRAは動いたでしょか?
動かなかった人はごめんなさい。高価なビデオボードが必要になりますので、又機会が有りましたら再チャレンジしてみてください。
動いた方はおめでとうございます!
公開は出来ませんが好きなアイドルなどをモデル化したり、色々とチャレンジしてみてください。
詳しいLoRAの使い方はこちらで紹介しています。